
问题的提出
网友bercmisir在院内留言,针对php手册中的call_user_func函数的文档一事,大致如下:
http://php.net/manual/en/function.call-user-func.php
其中parameter下有这样一句话:
Note: Note that the parameters for call_user_func() are not passed by reference.
简单地翻译一下,是说这个函数的参数是不能依靠引用来传递的。
还有一个例子:
error_reporting(E_ALL);
function increment(&$var)
$var++;
}
$a = 0;
call_user_func('increment', $a);
echo $a."\n";
call_user_func_array('increment', array(&$a)); // You can use this instead before PHP 5.3
echo $a."\n";
?>
输出是:
0
1
而网友bercmisir的问题在于:
call_user_func('increment', $a);输出是0,而call_user_func('increment', &$a);却输出是1,明明说不能依靠引用来传递。
寻根溯源
然后再进一步寻根溯源,这个Note的信息其实是http://bugs.php.net/bug.php?id=24931这个bug中最后处理的结果。
并且在call_user_func('increment', &$a);虽然输出了1的结果,但一般情况下,会有一个警告信息:Deprecated: Call-time pass-by-reference has been deprecated。
这是什么原因呢?
先看一个例子:
error_reporting(E_ALL);
function increment(&$var)
{
$var++;
$x = 1;
increment($x);
echo $x;
?>
结果为2,并且没有类似expected to be a reference, value given的警告信息,相反地,如果将第8行代码修改为&$x,将得到一个废除警告。从而得以验证,其实PHP在传递过程中,变量会根据形参需要的到底是引用还是值来自行决定传输的是引用还是值,并不需要显式地传递(相反显式传递是即将被废除的)。
继续深入
http://www.php.net/manual/en/language.references.pass.php
在php手册中,介绍引用的传递一节,在中间位置有一个Note说到:在函数调用时是不需要传引用的(也就是上节所说的显式调用),在5.3中如果显式调用会出来一个废除警告。
分析源码
有人说:在php中写入,everything is a reference。
查阅php源码,在./Zend/zend_compile.c的1579行有函数定义zend_do_pass_param。(php5.2.13)
其中有这样一句判断:
if (original_op == ZEND_SEND_REF && !CG(allow_call_time_pass_reference)) {打印废除警告。}
大概意思就是说,在传递的是引用,并且php.ini的allow_call_time_pass_reference为否的话,打印警告。
再看zend_do_pass_param使用的地方,可以发现是在parser阶段时,根据参数ZVAL结构体中元素的定义,来传递到底是var还是value还是reference。(php5.2.13 ./Zend/zend_language_parser.y/c 451/3593)
结论
引用其实类似linux里的文件硬链接一样,但和C语言中的指针是不相同的,在parser阶段php会根据上下文环境自行判断是传引用还是值。而本文所提到的call_user_function并不会自行判断传的是引用还是值。所以前面的例子call_user_function在传值的时候不管用,而在传引用的时候得出了正确结果(但其实还有一个废除警告)。

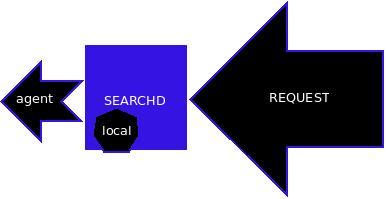 图1 一个searchd服务在接到请求时两种使用索引的示意图
图1 一个searchd服务在接到请求时两种使用索引的示意图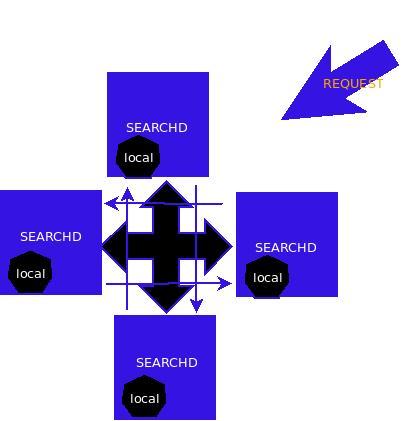 图2 一个简单的分布式搜索的例子
图2 一个简单的分布式搜索的例子 ==========尽职的安静的分隔线===========
==========尽职的安静的分隔线===========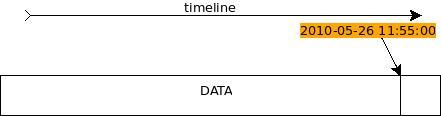 图1 数据在时间线上的示意图
图1 数据在时间线上的示意图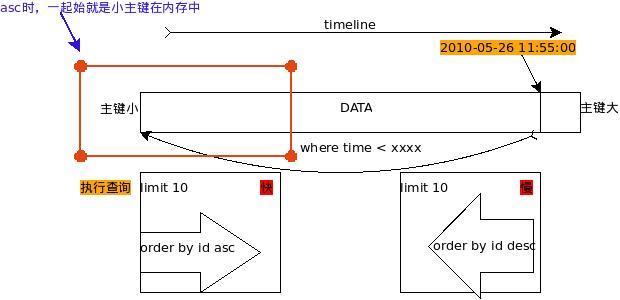 图2 第一条SQL语句快慢解释图
图2 第一条SQL语句快慢解释图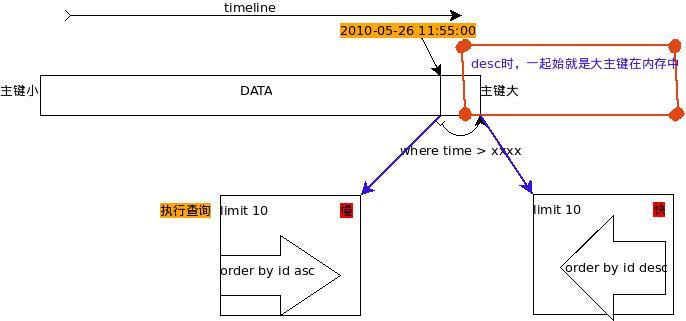 图2 第二条SQL语句快慢解释图
图2 第二条SQL语句快慢解释图

