
最近我(54chen)的兴趣都在android上,看到做的软件放到手持设备上的时候,找到了大学时光写delphi、gnome程序时久违的成就感。
下面是一些手记,这一系列的日志都将记录学习过程。
手记假设:
1.开发环境为ubuntu eclipse
2.你和我(54chen)一样有几年的java开发经验,对java基础不再进行描述
3.一开始就是以android2.2开始搞的,不排除后面的3出来,到时再另行通知
一 开发环境搭建 要开始开发Hello world,先要准备java环境(略),准备eclipse(略),再在eclipse上用software upadte安装上sdk的tools,再使用sdk的tools来安装platform(现在的最新版本是2.2),官方的文档和下载地址在http://developer.android.com/sdk/installing.html(洋文,被)。
因为是ubuntu 10.04,eclipse java都是可以apt-get install eclipse java6-sun-sdk(印象中是openjdk-6-jdk)来安装的。网上有许多切换openjdk到sunjdk的资料,不过提醒一点,这个openjdk似乎也一样可以用,如果切换成sunjdk的话,可能会遇到字体不正常的问题。
eclipse版本:3.5.2 Build id: M20100211-1343
第一步,要给eclipse安装一个android开发工具包
在eclipse的install new software上增加site:https://dl-ssl..com/android/eclipse/,安装这个传说中的ADT,其作用是一个最最基础的包,依靠这个包再进一步安装。(文件不大,所费时间不长)
第二步,下载SDK基础包:android-sdk_r07-linux_x86.tgz
http://developer.android.com/sdk/installing.html(洋文,被)
下载后解压。
假设解压后是/home/chen/下载/android-sdk-linux_x86,在eclipse>windows>proferences中找到Andriod,在SDK Location中写下这个地址。
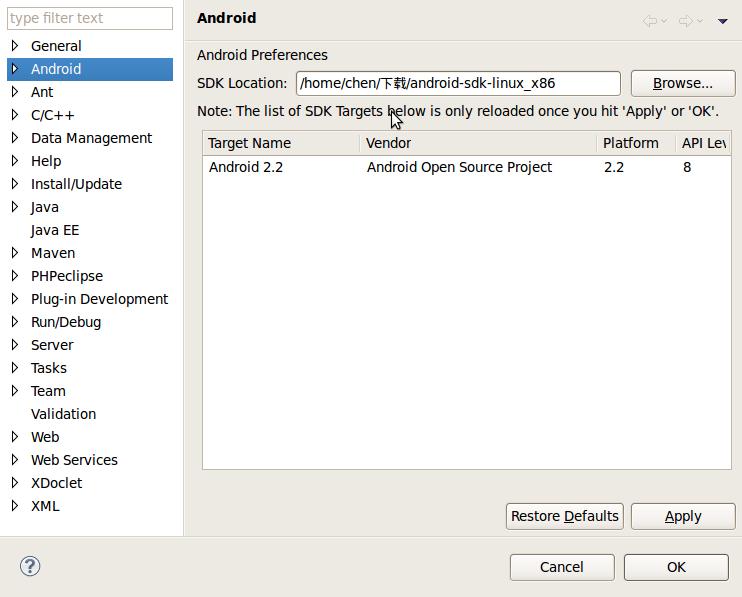
第三步,进一步安装需要的平台
eclipse>windows>Andriod SDK and AVD manager>available packages
打开后选platform 2.8,里面还有一些别的包,像的api啥的,是提供你简单调用 map啥的。
这一步会费很长的时间,东西比较大。
二 第一个android程序 Hello54chen
上面环境就ok了,来做第一个程序。
第一步 创建项目
file>new>new Android project
假设包名为com.chen.hello,类名为Show
会有一个关键的文件:com.chen.hello.Show
第二步 修改代码
打开这个文件,关键代码如下:
public class Show extends Activity {
/** Called when the activity is first created. */
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
//setContentView(R.layout.main); 这行是原来的 注释掉,下面是新添加的
TextView t = new TextView(this);
t.setText("你好,世界");
setContentView(t);
}
}
第三步 整一个新的AVD(andriod 虚拟设备)
eclipse>windows>Android SDK and AVD manager>Virtual Devices>new...
然后起个名,设置下存储大小等等。
第四步 run
run as android application后,选则刚刚建好的AVD,于是出来一个界面,要等啊等等啊等的,很长时间后,虚拟机才能进来,然后才会显示出来你的结果。
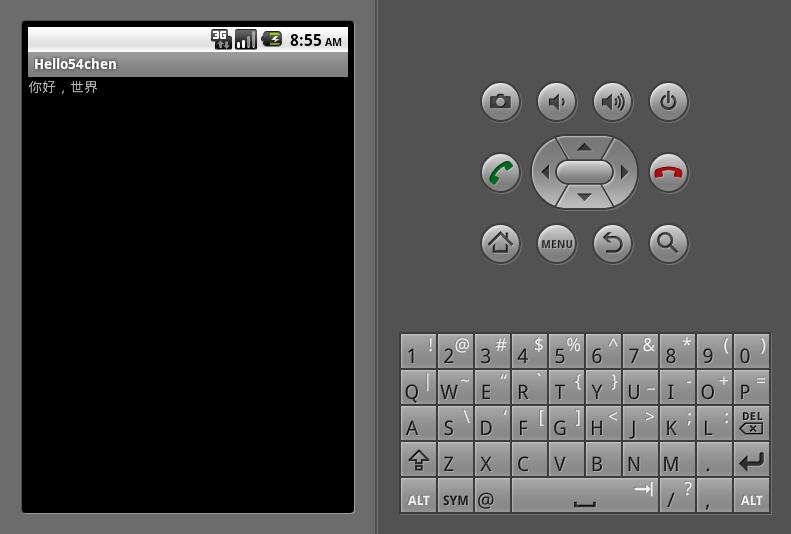

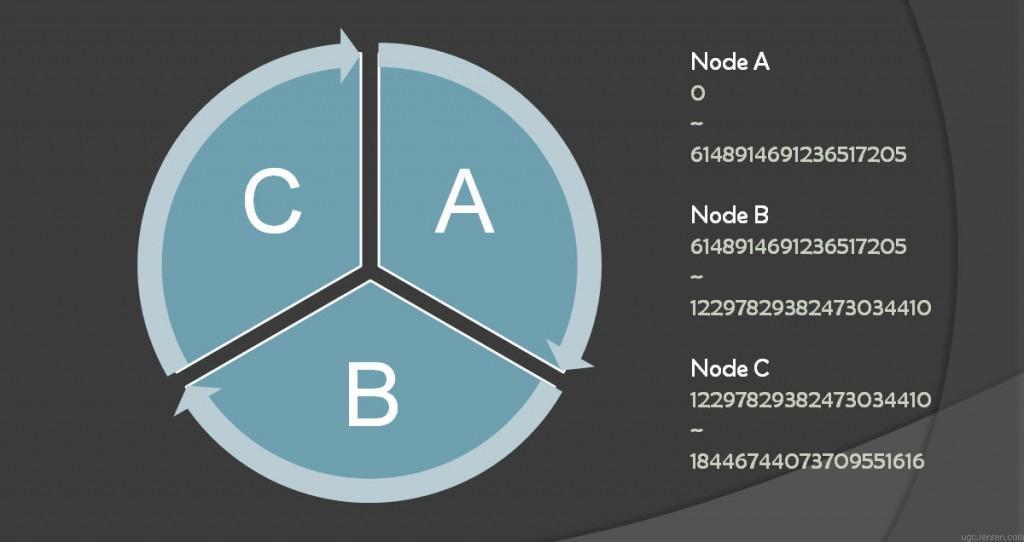 图1 key分布在三个节点的示意图
图1 key分布在三个节点的示意图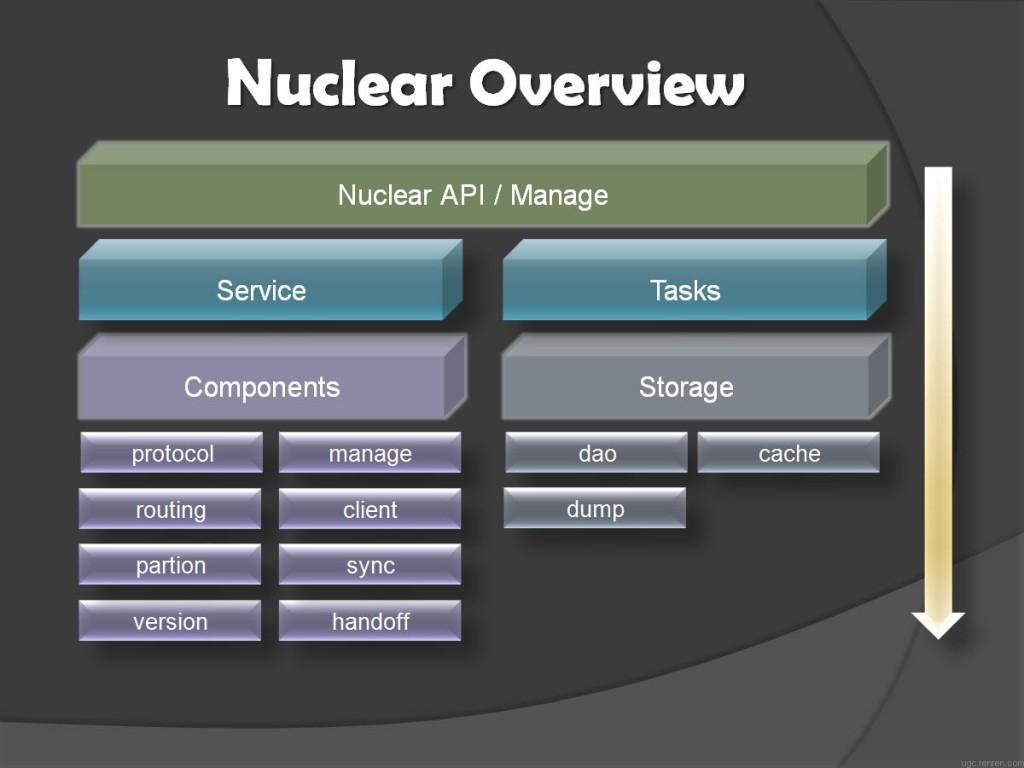 图2 Nuclear系统构架图
图2 Nuclear系统构架图 冷昊:人人网UGC团队成员,现和UGC技术团队一起为人人网用户在信息共享和传播的更加便捷做不懈努力,关注系统架构、分布式技术、数据挖掘。个人Blog: http://www.lenghao.com。可以通过电子邮件 jerome.leng@mail.com 联系到他。
冷昊:人人网UGC团队成员,现和UGC技术团队一起为人人网用户在信息共享和传播的更加便捷做不懈努力,关注系统架构、分布式技术、数据挖掘。个人Blog: http://www.lenghao.com。可以通过电子邮件 jerome.leng@mail.com 联系到他。
 陈臻(54chen):人人网UGC团队成员,技术组织哥学社创始人,PHPChina内核版主,业余时间混迹于各技术组织且乐此不疲。个人Blog:http://www.54chen.com/ 。可以通过电子邮件 cc0cc@126.com 联系到他。
陈臻(54chen):人人网UGC团队成员,技术组织哥学社创始人,PHPChina内核版主,业余时间混迹于各技术组织且乐此不疲。个人Blog:http://www.54chen.com/ 。可以通过电子邮件 cc0cc@126.com 联系到他。

