54chen在研究一个开源项目的时候,发现其使用的构建工具很特殊,叫Gradle,和ant maven类似,他提供的东西更加有感觉,不过冒似版本还不高,最新的0.9也只是一个预览版本。
名词解释
ant
当一个代码项目大了以后,每次重新编译,打包,测试等都会变得非常复杂而且重复,因此c语言中有make脚本来帮助这些工作的批量完成。在Java 中应用是平台无关性的,当然不会用平台相关的make脚本来完成这些批处理任务了,ANT本身就是这样一个流程脚本引擎,用于自动化调用程序完成项目的编译,打包,测试等。除了基于JAVA是平台无关的外,脚本的格式是基于XML的,比make脚本来说还要好维护一些。
maven
Maven是基于项目对象模型(POM),可以通过一小段描述信息来管理项目的构建,报告和文档的软件项目管理工具.
如果你已经有十次输入同样的Ant targets来编译你的代码、jar或者war、生成javadocs,你一定会自问,是否有有一个重复性更少却能同样完成该工作的方法。Maven便提供了这样一种选择,将你的注意力从作业层转移到项目管理层。Maven项目已经能够知道如何构建和捆绑代码,运行测试,生成文档并宿主项目网页.
项目的主页地址为:http://maven.apache.org/
Gradle
Gradle是一个基于Groovy的build工具——“Ease - Freedom - Power for your build
Gradle试图使用Groovy语法来提供Ant的灵活性;它支持多项目的创建,为Ivy提供了一个layer,提供了build-by-convention集成;而且它还让你获得许多类似Maven的功能比如传递依赖管理和约定大于配置。
Groovy
Groovy 是 JVM 的一个替代语言 — 替代 是指可以用 Groovy 在 Java 平台上进行 Java 编程,使用方式基本与使用 Java 代码的方式相同。在编写新应用程序时,Groovy 代码能够与 Java 代码很好地结合,也能用于扩展现有代码。目前的 Groovy 版本是 1.6.3,在 Java 1.4 和 Java 5 平台上都能使用,也能在 Java 6 上使用。
为何使用Gradle
尽管Ant没有内置的依赖管理是个事实,但是将Ivy整合到你build.xml中还是很简单的。Maven有构建脚本,只需要几行代码来配置就可以有许多功能:依赖管理、内置的编译和打包应用的任务、与Jetty的集成、干净的项目web网址,与cobertura的集成、pmd或者findbugs。
Maven和Ant就只是我们的选择么?是否还有比它们更好的选择?在过去的几年中,我们看到很多项目,他们使用的工具不再使用XML来定义构建逻辑,而是真正的编程语言像Groovy、Ruby、Python,它们经常允许依赖管理。这里有几个:GRADLE 、Gant、Kundo、 Raven、 Buildr。
如何使用Gradle
用Groovy语法(相当类似java)写好构建的逻辑。类似下面这个(elasticsearch项目的):
import java.text.SimpleDateFormat
defaultTasks "clean", "release"
usePlugin BasePlugin
archivesBaseName = 'elasticsearch'
buildTime = new Date()
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd'T'HH:mm:ss");
sdf.setTimeZone(TimeZone.getTimeZone("UTC"));
buildTimeStr = sdf.format(buildTime)
versionNumber = '0.5.1-SNAPSHOT'
explodedDistDir = new File(distsDir, 'exploded')
explodedDistLibDir = new File(explodedDistDir, 'lib')
explodedDistBinDir = new File(explodedDistDir, 'bin')
explodedDistConfigDir = new File(explodedDistDir, 'config')
allprojects {
group = 'org.elasticsearch'
version = versionNumber
plugins.withType(JavaPlugin).whenPluginAdded {
sourceCompatibility = 1.6
targetCompatibility = 1.6
}
repositories {
mavenCentral()
mavenRepo urls: 'http://repository.jboss.com/maven2/'
}
}
configurations {
dists
distLib {
visible = false
}
}
dependencies {
distLib project(':elasticsearch')
}
task explodedDist(dependsOn: [configurations.distLib], description: 'Builds a minimal distribution image') << {
[explodedDistDir, explodedDistLibDir, explodedDistBinDir, explodedDistConfigDir]*.mkdirs()
// remove old elasticsearch files
ant.delete { fileset(dir: explodedDistLibDir, includes: "$archivesBaseName-*.jar") }
copy {
from configurations.distLib
into explodedDistLibDir
}
copy { from('bin'); into explodedDistBinDir }
copy { from('config'); into explodedDistConfigDir }
copy {
from('.')
into explodedDistDir
include 'LICENSE.txt'
include 'NOTICE.txt'
include 'README.textile'
}
ant.chmod(dir: "$explodedDistDir/bin", perm: "ugo+rx", includes: "**/*")
}
task zip(type: Zip) {
dependsOn explodedDist
// classifier = 'all'
}
zip.doFirst {task ->
zipRootFolder = "$archivesBaseName-${-> version}"
task.configure {
zipFileSet(dir: explodedDistDir, prefix: zipRootFolder) {
exclude 'bin/*'
}
zipFileSet(dir: explodedDistDir, prefix: zipRootFolder, fileMode: '775') {
include 'bin/*'
exclude 'bin/*.*'
}
zipFileSet(dir: explodedDistDir, prefix: zipRootFolder) {
include 'bin/*.*'
}
}
}
task release(dependsOn: [zip]) {
}
task wrapper(type: Wrapper) {
gradleVersion = '0.8'
jarPath = 'gradle'
}
到Gradle下载zip包,解压到任何位置,设置环境变量中的GRADLE_HOME过程此位置,path中增加gradle的bin目录,http://www.gradle.org (杯具,需翻)
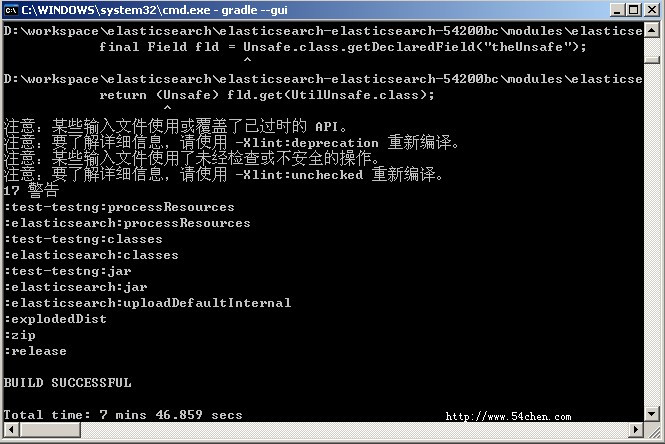
到项目目录下直接运行 gradle,编译成功有如下提示:
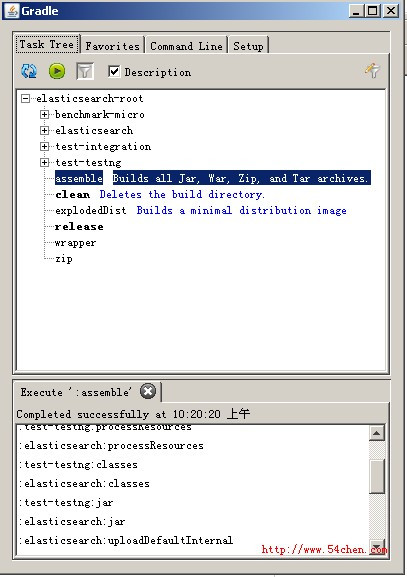
如果直接运行 gradle --gui,还能以gui的模式来选择,非常人性化:
本文作者:
54chen(陈臻),人人网分布式存储研究人员,业余时间混迹于各技术组织且乐此不疲。目前关注实施PHP培训。对flex等前端技术有一点研究。
个人技术站点:http://www.54chen.com/ 。可以通过电子邮件 cc0cc@126.com 联系到他。
本文提到的网址
Gradle: http://www.gradle.org
国内的评论:http://news.csdn.net/n/20090313/124106.html
的一些讨论:http://stackoverflow.com/questions/1163173/why-use-gradle-instead-of-ant-or-maven
