 *从小培养华丽丽的山寨*/>
介绍
*从小培养华丽丽的山寨*/>
介绍
Sphinx[英] [sfɪŋks] [美] [sfɪŋks]
出自俄罗斯的开源全文搜索引擎软件Sphinx,单一索引最大可包含1亿条记录,在1千万条记录情况下的查询速度为0.x秒(毫秒级)。Coreseek是一款基于Sphinx的开源检索引擎,支持Tb级的全文数据索引,专门为中文用户提供免费开源的中文全文检索系统。
下载
wget http://www.coreseek.cn/uploads/csft/3.2/csft-3.2.12.tar.gz
wget http://www.coreseek.cn/uploads/csft/3.2/mmseg-3.2.12.tar.gz
解压
tar -zxvf mmseg-3.2.12.tar.gz
tar -zxvf csft-3.2.12.tar.gz
中文依赖下载和安装
wget http://ftp.gnu.org/pub/gnu/libiconv/libiconv-1.13.tar.gz
tar zxvf libiconv-1.13.tar.gz
cd libiconv-1.13/
./configure --with-libiconv-prefix
make
make install
建立系统动态链接
在/etc/ld.so.conf中加一行/usr/local/lib,运行ldconfig。 ld.so.conf和ldconfig是维护系统动态链接库的。真不明白为什么iconv库安装时不把这一步也做了
安装mmseg分词
cd mmseg-3.2.12
yum -y install glibc-common libtool autoconf automake mysql-devel expat-devel
aclocal
libtoolize –force
automake –add-missing
autoconf
autoheader
./configure –prefix=/usr/local/mmseg3
make
make install
cp -f src/*/*.h /usr/local/mmseg3/include/mmseg/
安装sphinx
cd ..
cd csft-3.2.12
aclocal
libtoolize –force
automake –add-missing
autoconf
autoheader
perl -pi -e ’s/lpthread/lpthread -liconv/g’ src/Makefile*
./configure –prefix=/usr/local/coreseek –enable-id64 –without-python –with-mysql –with-mmseg –with-mmseg-includes=/usr/local/mmseg3/include/mmseg/ –with-mmseg-libs=/usr/local/mmseg3/lib/
perl -pi -e ’s/lpthread/lpthread -liconv/g’ src/Makefile*
make
make install
cd /usr/local/coreseek/etc/
cp sphinx.conf.dist csft.conf
修改配置中文支持
vim csft.conf
找到charset_type行,修改为:
charset_dictpath = /usr/local/coreseek/dict/
charset_type = zh_cn.utf-8
生成字典:
cd /root/install/mmseg-3.2.12/data/
/usr/local/mmseg3/bin/mmseg -u unigram.txt
mkdir -p /usr/local/coreseek/dict/
mv unigram.txt.uni /usr/local/coreseek/dict/uni.lib
增加mmseg配置:
vim /usr/local/coreseek/dict/mmseg.ini
mmseg.ini配置:(请将其放置到词典文件uni.lib所在的目录,并在文件结尾空两行)
[mmseg]
merge_number_and_ascii=0; ;合并英文和数字 abc123/x
number_and_ascii_joint=-; ;定义可以连接英文和数字的字符
compress_space=1; ;暂不支持
seperate_number_ascii=0; ;就是将字母和数字打散
索引
touch /data/exceptions.txt
bin/indexer –all
搜中文
bin/search 我爱

 ------------------英文大爱-----------------------
------------------英文大爱-----------------------
 图1 人人网公共主页页面
图1 人人网公共主页页面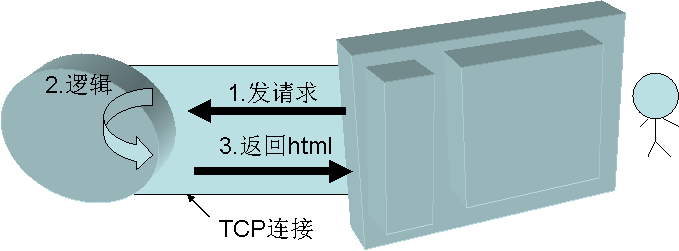 图2 一个传统的http请求过程
图2 一个传统的http请求过程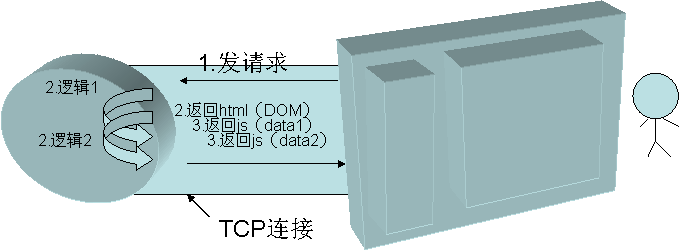 图3 pipe的请求过程
图3 pipe的请求过程
