前言
五一长假归来,休息长时间很有点不习惯,回到已经有些不适应了。
见到鸟哥的一文:深入理解PHP之require/include顺序 http://www.laruence.com/2010/05/04/1450.html
忍不住继续再深入了一下下,在此记录一下深入的过程,以供以后查阅。
普及 在php手册中:
require() is identical to include() except upon failure it will also produce a fatal E_ERROR level error. In other words, it will halt the script whereas include() only emits a warning (E_WARNING) which allows the script to continue.就是说在失败的时候,require是会中止php运行的,而include是可以继续运行的。
倒底有什么样的区别呢?我们带着这个疑问来一起进入PHP的核心代码。
下面是一个PHP运行过程的图(这个图是出自哪里的?鸟哥画的?)
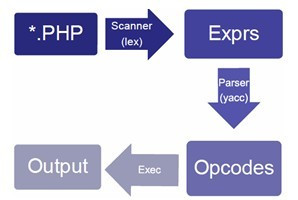
补习一下:lex是代码扫描器,扫描代码用的,yacc是Yet Another Compiler Compiler,作用是把任何一种代码的语法转成yacc语法,yacc就是解析器(真TMD绕)。
lex在c下的后缀是*.l yacc是*.y
正题 下面看作记录:
cc@cc-laptop:/opt/workspace$ svn checkout http://svn.php.net/repository/php/php-src/branches/PHP_5_3 php-src-5.3开始深入:
从svn取最新的php源代码。
cc@cc-laptop:/opt/workspace/php-src-5.3$ find . -type f -name "*.l" -exec grep -Hn "require_once" {} \;
./Zend/zend_language_scanner.l:1093:"require_once" {
寻找lex代码扫描器文件中出现require_once的地方,zend_language_scanner.l的1093行。
1093 "require_once" {
1094 return T_REQUIRE_ONCE;
1095 }
然后再搜一下T_REQUIRE_ONCE,
cc@cc-laptop:/opt/workspace/php-src-5.3$ find . -type f -name "*.y" -exec grep -Hn "T_INCLUDE" {} \;
./Zend/zend_language_parser.y:52:%left T_INCLUDE T_INCLUDE_ONCE T_EVAL T_REQUIRE T_REQUIRE_ONCE
./Zend/zend_language_parser.y:985: | T_INCLUDE expr { zend_do_include_or_eval(ZEND_INCLUDE, &$$, &$2 TSRMLS_CC); }
./Zend/zend_language_parser.y:986: | T_INCLUDE_ONCE expr { zend_do_include_or_eval(ZEND_INCLUDE_ONCE, &$$, &$2 TSRMLS_CC); }
在985行附近,有这样一群代码:
internal_functions_in_yacc:
T_ISSET '(' isset_variables ')' { $$ = $3; }
| T_EMPTY '(' variable ')' { zend_do_isset_or_isempty(ZEND_ISEMPTY, &$$, &$3 TSRMLS_CC); }
| T_INCLUDE expr { zend_do_include_or_eval(ZEND_INCLUDE, &$$, &$2 TSRMLS_CC); }
| T_INCLUDE_ONCE expr { zend_do_include_or_eval(ZEND_INCLUDE_ONCE, &$$, &$2 TSRMLS_CC); }
| T_EVAL '(' expr ')' { zend_do_include_or_eval(ZEND_EVAL, &$$, &$3 TSRMLS_CC); }
| T_REQUIRE expr { zend_do_include_or_eval(ZEND_REQUIRE, &$$, &$2 TSRMLS_CC); }
| T_REQUIRE_ONCE expr { zend_do_include_or_eval(ZEND_REQUIRE_ONCE, &$$, &$2 TSRMLS_CC); }
;
于是乎,我们需要继续深入寻找zend_do_include_or_eval,
cc@cc-laptop:/opt/workspace/php-src-5.3$ find . -type f -name "*.c" -exec grep -Hn "zend_do_include_or_eval" {} \;
./Zend/zend_compile.c:4317:void zend_do_include_or_eval(int type, znode *result, const znode *op1 TSRMLS_DC) /* */
zend_do_include_or_eval中组装了一个结构体,ZEND_INCLUDE_OR_EVAL。
再在zend_vm_def.h中找到ZEND_VM_HANDLER(73, ZEND_INCLUDE_OR_EVAL, CONST|TMP|VAR|CV, ANY):
switch (Z_LVAL(opline->op2.u.constant)) {代码略}
中间关键的一句是:
new_op_array = compile_filename(Z_LVAL(opline->op2.u.constant), inc_filename TSRMLS_CC);
在zend_complie.h文件中:
ZEND_API zend_op_array *compile_filename(int type, zval *filename TSRMLS_DC);
这个函数定义在zend_language_scaner.l文件中,找出最核心的代码:
if (open_file_for_scanning(file_handle TSRMLS_CC)==FAILURE) {
// require与include的差别:错误信息的显示级别(有bailout和无bailout)
if (type==ZEND_REQUIRE) { //require时
zend_message_dispatcher(ZMSG_FAILED_REQUIRE_FOPEN, file_handle->filename TSRMLS_CC);
zend_bailout();
} else {
zend_message_dispatcher(ZMSG_FAILED_INCLUDE_FOPEN, file_handle->filename TSRMLS_CC);
compilation_successful=0;
} else {代码略}
继续追踪zend_message_dispatcher可以在main/main.c文件中找到php_message_handler_for_zend函数:
//include输出错误信息时的级别为:E_WARNING
case ZMSG_FAILED_INCLUDE_FOPEN:
php_error_docref("function.include" TSRMLS_CC, E_WARNING, "Failed opening '%s' for inclusion (include_path='%s')", php_strip_url_passwd((char *) data), STR_PRINT(PG(include_path)));
break;
//require输出错误信息时的级别为:E_COMPILE_ERROR
代码略
总结 和开头PHP手册所说完全一致,require和include的区别在于,出现错误时,一个是error一个是warning。